
Un’interruzione del servizio su larga scala ha colpito l’infrastruttura globale di Microsoft questo giovedì 22 gennaio, colpendo milioni di utenti aziendali e privati. Aplicações essenziali per l’ambiente di lavoro moderno, come Outlook, Teams e l’intero pacchetto Microsoft 365, hanno registrato una significativa instabilità, impedendo l’accesso e l’utilizzo delle loro funzionalità principali.
I problemi hanno iniziato a essere segnalati intorno alle 11:40, ora Pacífico, e la società ha rapidamente confermato che stava indagando su un difetto nella sua infrastruttura di rete. L’incidente Este arriva appena un giorno dopo un’interruzione più piccola ma correlata che aveva precedentemente segnalato possibili punti deboli nel sistema.
Sulle piattaforme di monitoraggio online si sono moltiplicate le segnalazioni di difficoltà di accesso, provenienti da diverse parti del mondo, tra cui América di Norte, Europa e Ásia. La situazione ha messo in luce la profonda dipendenza delle operazioni aziendali quotidiane dai servizi cloud, paralizzando le attività di innumerevoli organizzazioni.
Dettagli del problema tecnico identificato
La diagnosi iniziale di Microsoft indicava un guasto critico nei sistemi responsabili del bilanciamento del carico sulla sua rete. La tecnologia Essa è fondamentale per distribuire in modo efficiente il traffico dati e le richieste degli utenti tra i vari server dell’azienda. Quando questo meccanismo fallisce, i server possono sovraccaricarsi, con conseguenti rallentamenti diffusi, errori di login e, in molti casi, la totale impossibilità di accedere ai servizi. I team di ingegneri dell’Microsoft sono stati immediatamente mobilitati per isolare il componente difettoso e hanno iniziato a reindirizzare manualmente il traffico, una misura provvisoria per mitigare gli impatti mentre lavoravano alla soluzione definitiva al guasto nell’infrastruttura centrale. La complessità dell’ambiente cloud richiedeva un’attenta analisi per garantire che la soluzione non innescasse nuovi problemi a cascata.
Principali servizi e entità dell’interruzione
Il servizio di posta elettronica Outlook è stato tra le piattaforme più colpite, essendo responsabile del maggior volume di reclami da parte degli utenti. Inúmeras persone e aziende si sono trovate nell’impossibilità di inviare o ricevere messaggi, affrontando continue notifiche di errore che menzionavano problemi di connessione al server.
Allo stesso tempo, lo strumento di collaborazione Microsoft Teams ha subito un grave degrado delle sue prestazioni. Usuários ha riferito di non essere in grado di partecipare a riunioni virtuali, inviare messaggi in chat o accedere a file e canali condivisi, il che ha causato un’interruzione diretta dei flussi di lavoro remoti e delle comunicazioni interne delle aziende.
Anche il più ampio ecosistema Microsoft 365 è stato compromesso dal difetto. Difficoltà si sono estese all’accesso al centro amministrativo, strumento cruciale per i dipartimenti IT, e sono stati registrati problemi anche con le versioni online di applicazioni popolari come Word e Excel, influenzando la produttività a tutti i livelli.
La risposta ufficiale di Microsoft
Di fronte al crescente numero di segnalazioni e alla dimensione globale del problema, Microsoft ha utilizzato la pagina ufficiale sullo stato del servizio e i profili dei social media per tenere informati gli utenti. La società ha annunciato di aver identificato un’anomalia relativa a un recente cambiamento nella configurazione della rete e che stava invertendo questo cambiamento per ripristinare la normalità. La strategia di comunicazione di Essa mirava a offrire trasparenza e gestire le aspettative di milioni di clienti e amministratori IT che erano in attesa di una soluzione.
Gli ingegneri dell’azienda hanno concentrato i loro sforzi sulla stabilizzazione della rete principale prima di iniziare a elaborare il backlog delle attività in sospeso, come le e-mail non consegnate e le sincronizzazioni dei dati in sospeso. Microsoft ha avvertito che, anche dopo il ripristino dell’infrastruttura centrale, alcuni utenti potrebbero continuare a sperimentare effetti residui, come rallentamenti, fino a quando l’intero sistema non sarà tornato alla normalità. L’obiettivo principale era garantire un recupero completo e solido per prevenire il ripetersi dello stesso problema.
Impatto diretto sulle operazioni aziendali
L’interruzione ha causato notevoli problemi operativi alle aziende che strutturano le proprie attività attorno all’ecosistema cloud Microsoft.
I flussi di lavoro sono stati improvvisamente interrotti, con interi team incapaci di comunicare in modo efficace o di accedere a documenti e dati critici archiviati online.
L’incidente ha costretto molte organizzazioni ad attivare i propri piani di emergenza, rivolgendosi a piattaforme di comunicazione alternative o posticipando riunioni e scadenze importanti.
Questo evento è servito a ricordare duramente le vulnerabilità inerenti all’affidarsi a un unico fornitore di servizi cloud per le funzioni aziendali essenziali.
Reazioni e resoconti degli utenti globali
Sui social network e nei forum specializzati, professionisti di diversi settori hanno espresso la loro frustrazione per la sospensione delle loro attività. Muitos ha evidenziato come il fallimento abbia avuto un impatto diretto sulla produttività, soprattutto nei modelli di lavoro remoto e ibrido che si basano sulla collaborazione in tempo reale.
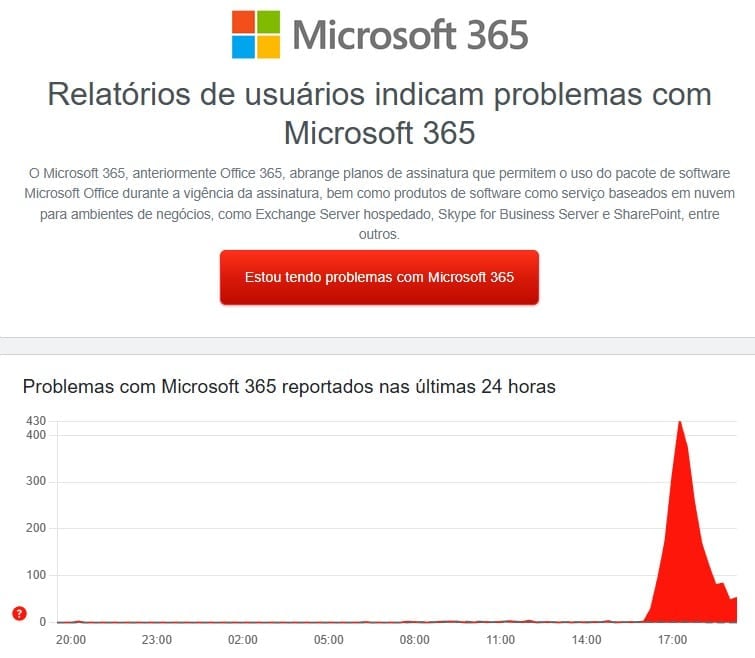
Piattaforme di monitoraggio come DownDetector hanno mostrato picchi massicci nelle notifiche dei problemi, con la maggior parte delle segnalazioni concentrate nei principali hub aziendali nell’Estados Unidos e Europa, espandendosi ad altre regioni man mano che la giornata lavorativa procedeva a livello globale.
Confronto con il fallimento del giorno precedente
Il verificarsi di problemi di servizio per il secondo giorno consecutivo ha sollevato serie preoccupazioni sulla stabilità e la resilienza dell’infrastruttura di Microsoft. Sebbene l’interruzione di mercoledì sia stata di durata più breve e di portata più limitata, l’incidente di giovedì è stato notevolmente più grave, prolungato e pervasivo, colpendo una gamma molto più ampia di servizi critici e suggerendo l’esistenza di un problema di fondo più complesso.
Misure di mitigazione e ripristino
Più tardi nel pomeriggio, Microsoft ha riferito che le sue azioni di mitigazione avevano avuto successo e che i servizi stavano iniziando a stabilizzarsi per la maggior parte degli utenti. Il rollback della configurazione di rete problematica è stato completato, consentendo ai sistemi di bilanciamento del carico di tornare a funzionare correttamente.
L’azienda ha mantenuto un monitoraggio intensivo dell’ambiente per garantire il mantenimento della stabilità e per elaborare l’ampio arretrato di dati accumulato durante i tempi di inattività. La promessa è che verrà rilasciato un rapporto dettagliato post-incidente per fornire una spiegazione completa della causa principale del guasto.
