
Uma interrupção significativa nos serviços da Microsoft gerou instabilidade para milhões de usuários corporativos e individuais em todo o mundo nesta quinta-feira, 22 de janeiro. A falha, que começou a ser notada por volta das 11h40 no horário do Pacífico, impactou diretamente o acesso e a funcionalidade de ferramentas essenciais como o Microsoft 365, o serviço de e-mail Outlook e a plataforma de comunicação Teams, afetando a produtividade em diversas regiões.
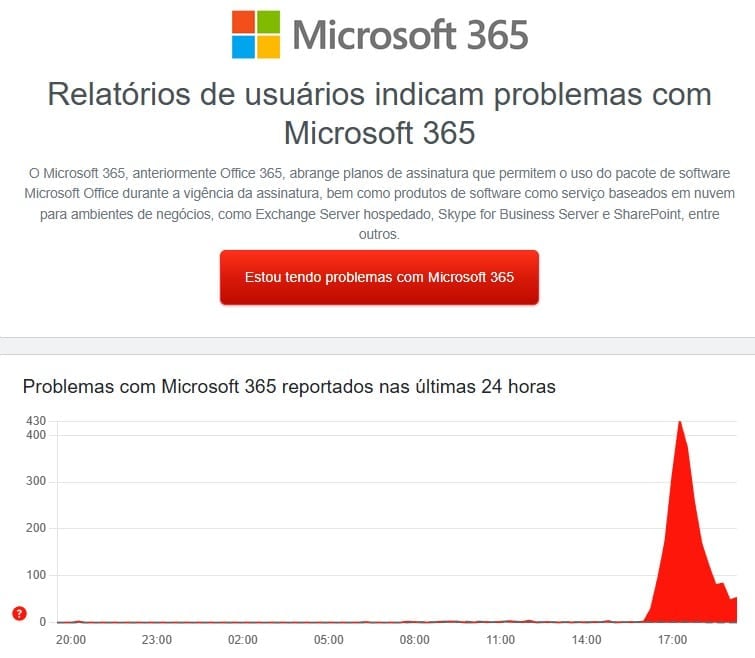
Relatos de usuários em plataformas de monitoramento online, como o DownDetector, dispararam em questão de minutos, com queixas concentradas na América do Norte, Europa e partes da Ásia. As dificuldades mais comuns incluíam a impossibilidade de enviar ou receber e-mails, falhas de login em aplicativos do pacote 365 e a incapacidade de participar de reuniões virtuais ou acessar canais de comunicação no Teams.
A Microsoft rapidamente reconheceu o problema por meio de sua página oficial de status de serviço e canais de comunicação. A empresa confirmou que estava investigando uma falha potencial na infraestrutura de rede, que estaria afetando o balanceamento de carga entre seus servidores e causando a degradação generalizada dos serviços para um grande número de clientes.
O epicentro da falha na rede
A causa primária apontada pela equipe de engenharia da Microsoft foi um problema complexo em sua infraestrutura de rede global, especificamente nos sistemas responsáveis pelo balanceamento de carga. Essa tecnologia é fundamental para distribuir o tráfego de dados de maneira eficiente entre múltiplos servidores, garantindo que nenhum deles fique sobrecarregado. Quando esse sistema falha, o resultado é um congestionamento massivo que impede as solicitações dos usuários de chegarem aos seus destinos, resultando em erros de conexão, lentidão extrema e indisponibilidade total dos serviços. A falha desta quinta-feira demonstrou a interconexão crítica desses sistemas, onde um problema em um componente central pode desencadear um efeito cascata em todo o ecossistema.
A investigação inicial sugeriu que uma atualização de configuração na rede pode ter sido o gatilho para o incidente, afetando a forma como os dados eram roteados globalmente. Essa falha de roteamento impediu que os servidores de autenticação e de serviços específicos, como os do Outlook e Teams, se comunicassem corretamente, isolando-os efetivamente da rede pública. A complexidade do ambiente de nuvem da Microsoft significa que a identificação da causa exata e a implementação de uma solução segura exigem uma análise cuidadosa para evitar a introdução de novos problemas, o que explica o tempo necessário para a restauração completa das funcionalidades para todos os usuários afetados.
Impacto direto na rotina de milhões de usuários
Para os usuários do Outlook, o serviço de e-mail foi o mais visivelmente afetado. As reclamações variavam desde a completa incapacidade de acessar a caixa de entrada até e-mails que ficavam presos na caixa de saída sem serem enviados. Mensagens de erro informando sobre falhas temporárias de servidor se tornaram comuns, interrompendo o fluxo de comunicação essencial para operações comerciais.
No Microsoft Teams, a espinha dorsal da colaboração para muitas empresas que operam em regime remoto ou híbrido, o impacto foi igualmente severo. Usuários relataram dificuldades para iniciar ou ingressar em videochamadas, falhas no carregamento de históricos de chat e a impossibilidade de acessar canais e arquivos compartilhados, paralisando projetos e reuniões importantes.
A instabilidade não se limitou ao Outlook e Teams. Todo o pacote Microsoft 365 sentiu os efeitos, com usuários enfrentando problemas para acessar e editar documentos no Word e Excel online. Além disso, o centro de administração da plataforma ficou inacessível para muitos gestores de TI, impedindo-os de diagnosticar problemas ou gerenciar as contas de suas organizações.
Serviços de segurança e conformidade, como o Microsoft Defender e o Microsoft Purview, que são cruciais para a proteção de dados corporativos, também foram afetados pela falha de infraestrutura. Essa interrupção simultânea em múltiplas frentes destacou a profunda dependência das empresas em relação ao ecossistema integrado da Microsoft.
A resposta oficial da Microsoft
Desde os primeiros relatos, a Microsoft adotou uma postura de comunicação ativa para manter os clientes informados sobre o andamento da situação. A empresa utilizou sua conta oficial no X (antigo Twitter) dedicada ao status do Microsoft 365, bem como o painel de saúde do serviço no centro de administração, para fornecer atualizações regulares sobre a investigação e as medidas de mitigação.
A primeira comunicação oficial confirmou a existência de um problema generalizado e informou que as equipes de engenharia haviam sido mobilizadas para identificar a causa raiz. As atualizações subsequentes forneceram mais detalhes técnicos, atribuindo a falha a um problema de rede e, mais tarde, a uma questão de balanceamento de carga, o que ajudou a tranquilizar os administradores de TI.
A empresa também detalhou as ações que estavam sendo tomadas, como o redirecionamento do tráfego para infraestruturas alternativas saudáveis e a reversão de uma alteração de rede que foi identificada como a provável origem do incidente. Essa transparência foi crucial para ajudar as empresas a gerenciar as expectativas e planejar suas próprias medidas de contingência.
Consequências para a produtividade corporativa global
A interrupção dos serviços da Microsoft nesta quinta-feira serve como um forte lembrete da vulnerabilidade das operações comerciais modernas, que dependem massivamente de serviços em nuvem. Para inúmeras organizações em todo o mundo, a paralisação de ferramentas como Outlook e Teams significou uma perda direta de produtividade, com funcionários incapazes de comunicar, colaborar ou acessar documentos essenciais para suas tarefas diárias. O trabalho remoto e os modelos híbridos, que se tornaram a norma para muitas empresas, foram particularmente atingidos, pois a infraestrutura digital que os sustenta ficou temporariamente fora do ar. Departamentos de tecnologia da informação foram sobrecarregados com um volume extraordinário de chamados de suporte de funcionários frustrados, desviando recursos que seriam utilizados em outras iniciativas estratégicas. O incidente forçou muitas equipes a recorrerem a plataformas alternativas e planos de contingência, destacando a necessidade de estratégias de resiliência digital mais robustas, incluindo redundância de serviços e protocolos claros para lidar com falhas de provedores de nuvem.
Um histórico recente de instabilidade
Este incidente ganha uma dimensão maior de preocupação por ter ocorrido apenas um dia após uma falha de menor escala, registrada na quarta-feira, 21 de janeiro. A interrupção anterior também afetou o acesso ao Microsoft Teams e a outras partes do ecossistema 365, embora tenha sido resolvida em poucas horas e com um impacto geográfico mais limitado.
A ocorrência de dois problemas significativos em dias consecutivos levanta questões sobre a estabilidade e a resiliência da infraestrutura global da Microsoft. A repetição de falhas pode levar clientes corporativos a reavaliar seus contratos de nível de serviço (SLAs) e a explorar opções de redundância com outros provedores para garantir a continuidade dos negócios.
O processo de restauração dos sistemas
A restauração dos serviços foi um processo gradual e controlado. A primeira medida de mitigação implementada pela Microsoft envolveu o redirecionamento do tráfego de rede para componentes de infraestrutura que não foram afetados pela falha inicial. Essa ação ajudou a aliviar a pressão sobre os sistemas sobrecarregados e permitiu que alguns serviços começassem a se recuperar.
No final da tarde, horário da costa leste dos EUA, a empresa anunciou que a infraestrutura principal havia sido recuperada e que a maioria dos serviços estava voltando à normalidade. No entanto, alertaram para efeitos residuais, como lentidão e atrasos no processamento de e-mails em fila, enquanto os sistemas lidavam com o acúmulo de solicitações gerado durante o período de inatividade.
Investigação da causa raiz continua
Embora os serviços tenham sido amplamente restaurados, a Microsoft se comprometeu a conduzir uma análise pós-incidente completa e detalhada. A empresa afirmou que irá divulgar um relatório explicando a causa raiz do problema e as medidas que serão implementadas para fortalecer a resiliência de sua rede e evitar que falhas semelhantes ocorram no futuro.
