
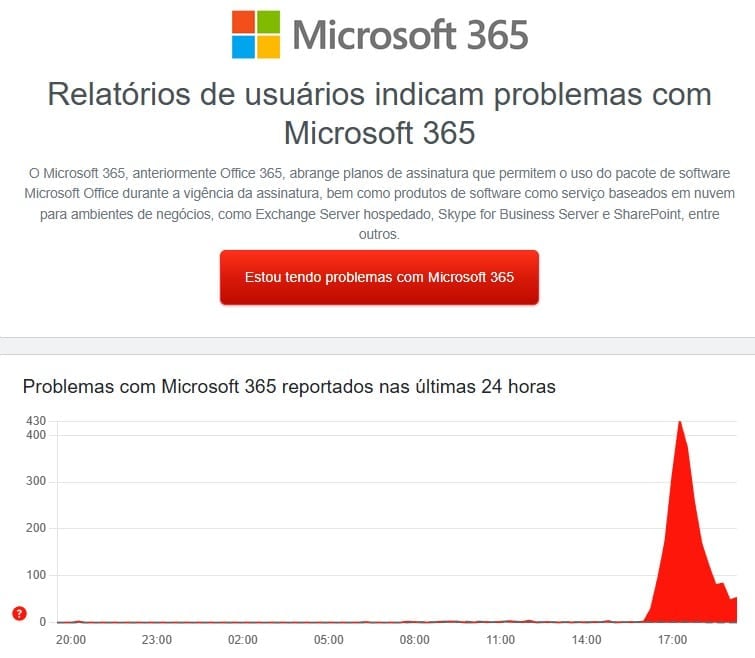
Una interrupción del servicio a gran escala afectó la infraestructura global de Microsoft este jueves 22 de enero y afectó a millones de usuarios corporativos e individuales. Aplicações esenciales para el entorno de trabajo moderno, como Outlook, Teams y todo el paquete Microsoft 365, registraron una importante inestabilidad, impidiendo el acceso y uso de sus principales funcionalidades.
Los problemas comenzaron a reportarse alrededor de las 11:40 am hora Pacífico, y la compañía rápidamente confirmó que estaba investigando una falla en su infraestructura de red. El incidente Este se produce apenas un día después de una interrupción menor pero relacionada que previamente había señalado posibles debilidades en el sistema.
Los informes sobre dificultades de acceso se han multiplicado en las plataformas de monitoreo en línea, provenientes de diferentes partes del mundo, incluidas América de Norte, Europa y Ásia. La situación expuso la profunda dependencia de las operaciones comerciales diarias de los servicios en la nube, paralizando las actividades en innumerables organizaciones.
Detalles del problema técnico identificado
El diagnóstico inicial de Microsoft apuntó a una falla crítica en los sistemas encargados de equilibrar la carga en su red. La tecnología Essa es esencial para distribuir eficientemente el tráfico de datos y las solicitudes de los usuarios entre los distintos servidores de la empresa. Quando este mecanismo falla, los servidores pueden sobrecargarse, provocando ralentizaciones generalizadas, errores de inicio de sesión y, en muchos casos, la total imposibilidad de acceder a los servicios. Los equipos de ingeniería de Microsoft se movilizaron inmediatamente para aislar el componente defectuoso y comenzaron a desviar el tráfico manualmente, una medida provisional para mitigar los impactos mientras trabajaban en la solución definitiva a la falla en la infraestructura central. La complejidad del entorno de la nube requirió un análisis cuidadoso para garantizar que la solución no desencadenara nuevos problemas en cascada.
Principales servicios y alcance de la interrupción
El servicio de correo electrónico Outlook estuvo entre las plataformas más afectadas, siendo responsable del mayor volumen de quejas de los usuarios. Inúmeras personas y empresas se encontraron sin poder enviar o recibir mensajes, enfrentando constantes notificaciones de error que mencionaban problemas para conectarse al servidor.
Al mismo tiempo, la herramienta de colaboración Microsoft Teams sufrió una grave degradación en su rendimiento. Usuários informó que no podían unirse a reuniones virtuales, enviar mensajes en chats ni acceder a archivos y canales compartidos, lo que provocó una interrupción directa de los flujos de trabajo remotos y la comunicación interna de las empresas.
El ecosistema más amplio Microsoft 365 también se vio comprometido por la falla. Las dificultades se extendieron al acceso al centro administrativo, una herramienta crucial para los departamentos de TI, y también se registraron problemas con las versiones en línea de aplicaciones populares como Word y Excel, afectando la productividad en todos los ámbitos.
La respuesta oficial de Microsoft
Ante el creciente número de denuncias y la dimensión global del problema, Microsoft utilizó su página oficial de estado del servicio y sus perfiles en las redes sociales para mantener informados a los usuarios. La compañía anunció que había identificado una anomalía relacionada con un cambio reciente en la configuración de la red y que estaba revirtiendo este cambio para restaurar la normalidad. La estrategia de comunicación de Essa buscó ofrecer transparencia y gestionar las expectativas de millones de clientes y administradores de TI que esperaban una solución.
Los ingenieros de la empresa centraron sus esfuerzos en estabilizar la red principal antes de comenzar a procesar la acumulación de tareas pendientes, como correos electrónicos no entregados y sincronizaciones de datos que estaban en espera. Microsoft advirtió que, incluso después de la recuperación de la infraestructura central, algunos usuarios podrían seguir experimentando efectos residuales, como ralentizaciones, hasta que todo el sistema vuelva a la normalidad. El objetivo principal era garantizar una recuperación completa y sólida para evitar que se repitiera el mismo problema.
Impacto directo en las operaciones corporativas
La interrupción provocó importantes dolores de cabeza operativos para las empresas que estructuran sus actividades en torno al ecosistema de nube Microsoft.
Los flujos de trabajo se interrumpieron abruptamente y equipos enteros no pudieron comunicarse de manera efectiva ni acceder a documentos y datos críticos almacenados en línea.
El incidente obligó a muchas organizaciones a activar sus planes de contingencia, recurriendo a plataformas de comunicación alternativas o aplazando reuniones y plazos importantes.
Este evento sirvió como un claro recordatorio de las vulnerabilidades inherentes a depender de un único proveedor de servicios en la nube para funciones comerciales esenciales.
Reacciones e informes de usuarios globales
En redes sociales y foros especializados, profesionales de distintos sectores expresaron frustración por el cese de sus actividades. Muitos destacó cómo la falla afectó directamente la productividad, especialmente en modelos de trabajo remotos e híbridos que dependen de la colaboración en tiempo real.
Las plataformas de monitoreo como DownDetector mostraron picos masivos en las notificaciones de problemas, con la mayoría de los informes concentrados en los principales centros comerciales en Estados Unidos y Europa, expandiéndose a otras regiones a medida que avanzaba la jornada laboral a nivel mundial.
Comparación con el fracaso del día anterior
La aparición de problemas de servicio por segundo día consecutivo ha generado serias preocupaciones sobre la estabilidad y resistencia de la infraestructura de Microsoft. Aunque la interrupción del miércoles fue de menor duración y de alcance más limitado, el incidente del jueves fue notablemente más grave, prolongado y generalizado, afectó a una gama mucho más amplia de servicios críticos y sugirió la existencia de un problema subyacente más complejo.
Medidas de mitigación y recuperación
Más tarde esa misma tarde, Microsoft informó que sus acciones de mitigación habían sido exitosas y que los servicios estaban comenzando a estabilizarse para la mayoría de los usuarios. Se completó la reversión de la configuración de red problemática, lo que permite que los sistemas de equilibrio de carga vuelvan a funcionar correctamente.
La empresa mantuvo un seguimiento intensivo del entorno para garantizar que se mantuviera la estabilidad y procesar la gran acumulación de datos que se acumularon durante el tiempo de inactividad. La promesa es que se publicará un informe detallado posterior al incidente para proporcionar una explicación completa de la causa raíz del fallo.
