
Днем 20 февраля игроки из разных уголков планеты столкнулись с непреодолимыми барьерами на пути к своим любимым играм. Инцидент начался около 13:38 по времени Остина, США, и быстро перерос в сценарий массового отключения. Технический сбой произошел не из-за серверов игровой платформы, а из-за инфраструктуры Cloudflare, важной сети для передачи данных в Интернете.
Количество жалоб резко возросло за считанные минуты, подчеркнув серьезность ситуации для игрового сообщества. Веб-сайт, специализирующийся на мониторинге онлайн-сервисов, зафиксировал впечатляющий всплеск просмотров страниц на 431 000 всего за один час. Эти статистические данные служат термометром масштаба проблемы, которая затронула все: от первоначального входа в систему до транзакций внутри игр.
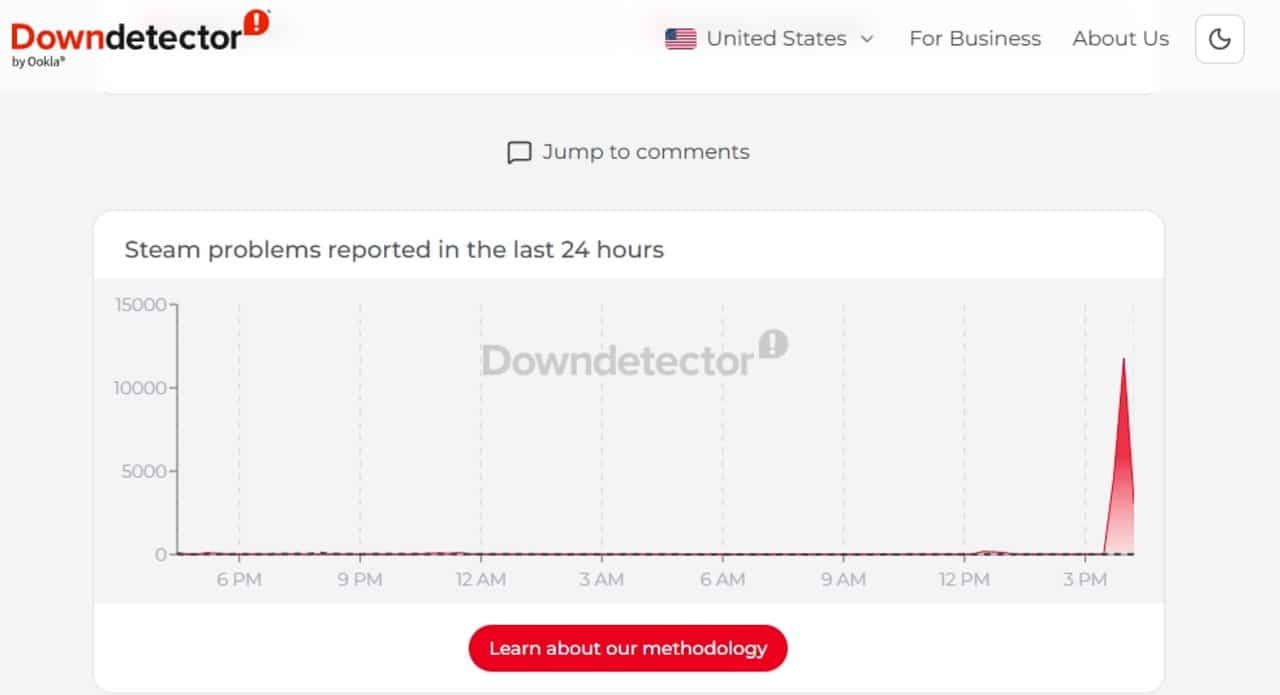
Перебои в предоставлении услуг подчеркнули хрупкость взаимосвязей между крупными поставщиками технологий. Пока Valve, компания, ответственная за платформу, поддерживала работоспособность своих внутренних систем, «путь» к ним был заблокирован. Зависимость от сетей доставки контента (CDN) означает, что внешний сбой может привести к мгновенной остановке глобальных операций.
По предварительным отчетам, большинство трудностей было связано с общением с сервером. Около 46% уведомлений об ошибках относились к прямому соединению, 29% указывали на недостатки в системе доменных имен (DNS) и 18% в интерфейсе прикладного программирования (API). Эти цифры рисуют картину структурного коллапса в распределении данных.
Техническая диагностика нестабильности
Cloudflare быстро отреагировала на причины сбоев в своей сети. Компания подтвердила наличие проблем с подключением, которые затронули несколько сервисов, включая портал one.one.one.one и управление ботами. Задержка HTTP-запросов резко возросла, особенно в центре обработки данных, расположенном в Ньюарке, что создало цифровое узкое место, препятствующее нормальному потоку информации.
Техническое воздействие вышло за рамки простой навигации и затронуло инструменты искусственного интеллекта компании. Сервис Workers AI показал высокий уровень ошибок, что еще больше усложнило ситуацию для разработчиков и платформ, которые зависят от этой инфраструктуры. Сложность системы распространения контента привела к каскадному возникновению проблемы.
Эксперты отмечают, что архитектура современного Интернета, несмотря на ее надежность, имеет критические точки отказа. Когда такой гигант, как Cloudflare, сталкивается с трудностями, неизбежен эффект домино, обрушивающий сервисы, которые теоретически не имели внутренних дефектов. Разрешение этих инцидентов требует точной координации для восстановления маршрутов передачи данных без перегрузки систем.
Влияние на ресурсы платформы
Пользовательский опыт на платформе Valve сильно ухудшился в период нестабильности. Хотя на официальных досках статуса магазин и сообщество выглядели как работающие, реальность для конечного потребителя была полной изоляцией. Несоответствие возникает из-за того, что внутренний статус сервера не отражает возможности пользователя получить к нему доступ через всемирную паутину.
Одним из наиболее критических моментов стала задержка инвентаризации популярных игр, таких как Counter-Strike. Медлительность обработки виртуальных предметов замедлила экономику игры, препятствуя обмену и покупке, что сразу же вызвало разочарование. Даже при условии, что диспетчеры соединений работают с доступностью 93,7%, оставшейся части, добавленной к внешнему сбою, было достаточно, чтобы вызвать функциональное отключение для миллионов людей.
Географический охват отключения электроэнергии
Географическое распределение разломов выявило неравномерную картину, по-разному влияющую на континенты и обнажающую сложность глобальной инфраструктуры. В Европе, в то время как в таких городах, как Амстердам и Лондон, менеджеры соединений оставались стабильными, во Франкфурте и Вене была зафиксирована высокая нагрузка, что указывает на локальную нагрузку на серверы. Азия пострадала от серьезных последствий: Гонконг был классифицирован как перегруженный, а основные хабы в Китае показали неубедительные данные о подключении, что позволяет предположить, что миллионы игроков остались без доступа. В Америке ситуация была сравнительно мягче: Сан-Паулу и несколько городов Северной Америки сообщили о нормальном статусе, хотя восприятие неудачи было глобальным из-за взаимосвязанного характера онлайн-игр.
Контекст сетевой инфраструктуры
Инцидент с Cloudflare не был единичным событием в интернет-экосистеме в тот день. Akamai, еще один гигант доставки контента, также столкнулся с недостатками в своей системе предоставления сертификатов. Такое совпадение проблем у крупных провайдеров подчеркивает сиюминутную уязвимость глобальной сети.
Одновременные сбои в различных магистральных сетях Интернета создают сложную ситуацию для быстрой диагностики. Для конечного пользователя разница между ошибкой игровой платформы и сбоем инфраструктуры невидима, что приводит к широко распространенному мнению, что услуга по контракту не предоставляется.
Реакция среди игроков
Социальные сети были завалены сообщениями о том, что пользователи не могут начать игровые сессии. Резкое прекращение работы в середине дня, в пиковое время в нескольких регионах, усилило недовольство. Дискуссионные форумы стали основным каналом обмена информацией о возвращении сервиса.
Игровое сообщество все чаще требует большей прозрачности и гибкости в решении технических проблем. Приостановление конкурентных матчей и невозможность доступа к платным цифровым библиотекам создают напряжение в отношениях между потребителями и платформами. Ожидания официальных заявлений были высокими на протяжении всего периода инцидента.
Этот эпизод служит напоминанием о цифровой зависимости от нескольких крупных узлов инфраструктуры. Централизация услуг в глобальных CDN обеспечивает преимущества в скорости и безопасности, но также повышает риски массовых сбоев. Устойчивость этих систем постоянно проверяется растущим объемом данных.
С постепенным восстановлением оказания услуг внимание переключается на профилактические меры. Участвующие компании должны проанализировать журналы ошибок, чтобы внести исправления, которые предотвратят дальнейшие каскадные сбои. Стабильность соединения стала такой же важной, как и сам игровой контент.
