يؤدي الفشل العالمي في Cloudflare إلى مقاطعة خدمات Steam وإحباط اللاعبين في العديد من البلدان

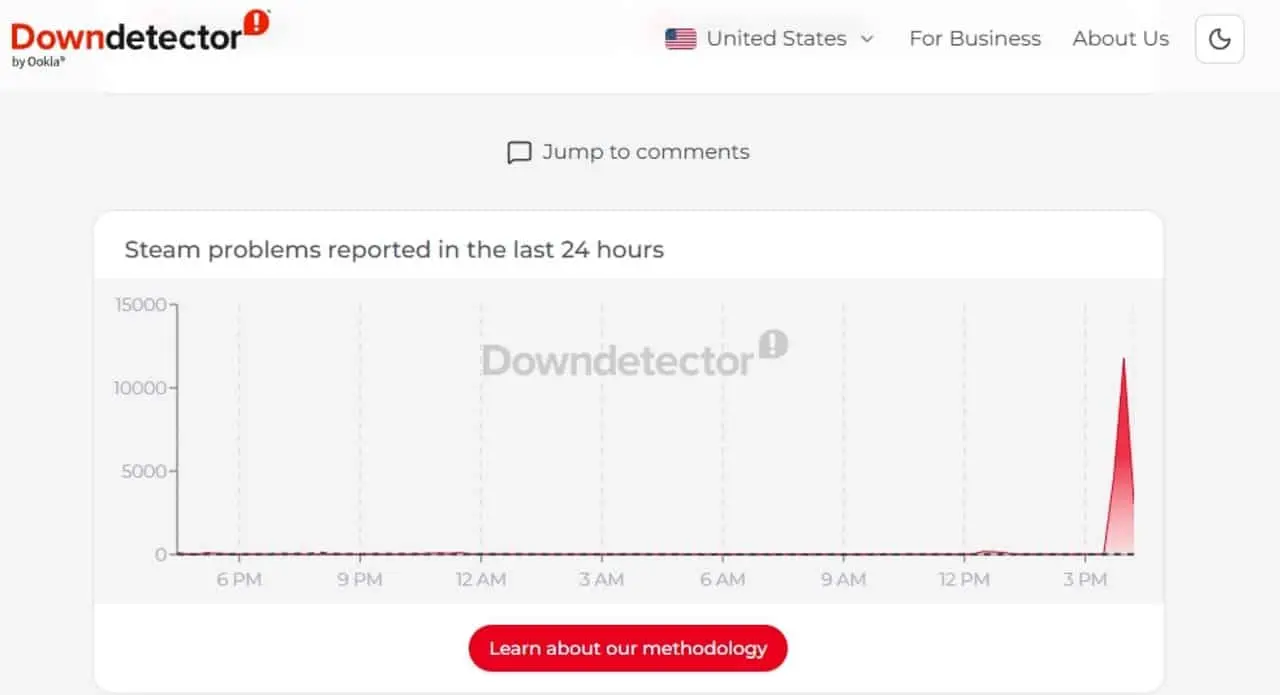
حدث انقطاع شديد في أنظمة توزيع المحتوى في البنية التحتية للإنترنت بعد ظهر يوم 20 فبراير، مما أدى إلى منع الوصول إلى منصة Steam على نطاق عالمي. بدأت الحادثة حوالي الساعة 1:38 مساءً بتوقيت أوستن وأسفرت عن عدد هائل من الشكاوى من المستخدمين الذين لم يتمكنوا من الوصول إلى مكتبات الألعاب والخدمات عبر الإنترنت الخاصة بهم. تم إرجاع المشكلة إلى فشل في خوادم Cloudflare، وهي شبكة ضرورية لتشغيل وأمن البوابات الكبيرة، مما أدى إلى سلسلة من ردود الفعل التي أثرت على اتصال ملايين الأشخاص.
وسلطت بيانات المراقبة في الوقت الفعلي الضوء على حجم الحدث، حيث سجلت ذروة بلغت 431 ألف مشاهدة للصفحة على موقع ويب متخصص في تتبع انقطاع الخدمة، كل ذلك في غضون ساعة واحدة فقط. ولم يقتصر الفشل على منطقة معينة، بل انتشر بسرعة عبر عدة قارات وكشف الاعتماد الحاسم الذي تتمتع به خدمات الترفيه الرقمية على شبكات توصيل المحتوى (CDNs) وأنظمة DNS الموزعة.
تحركت Cloudflare لتحديد مصدر عدم الاستقرار، واعترفت علنًا بوجود أخطاء في الاتصال في بنيتها التحتية. لاحظ الفنيون زيادة كبيرة في معدلات الخطأ على الصفحة الرئيسية للخدمة 1.1.1.1، بالإضافة إلى التعقيدات في إدارة الروبوتات وخدمة Workers AI. ومن النقاط المهمة الأخرى التي تم تحديدها هي الكمون العالي في طلبات HTTP التي يعالجها مركز بيانات نيوارك (EWR)، مما ساهم بشكل حاسم في البطء وعدم إمكانية الوصول من قبل المستخدمين النهائيين.
تشخيص الانقطاع الفني
تعتمد بنية الإنترنت الحديثة على خدمات مثل Cloudflare، التي تعمل بمثابة وسطاء حيويين بين الخوادم الأصلية والمستخدمين، مما يوفر الحماية ضد هجمات DDoS وتحسين حركة المرور. عندما تفشل هذه الطبقة الوسطى، يتم قطع الوصول إلى الخدمة النهائية، حتى لو كانت خوادم شركة الألعاب تعمل بشكل طبيعي. أصبح تعقيد هذا الاعتماد المتبادل واضحًا عندما أدت المشكلات الموجودة في عقد معينة من الشبكة إلى ظهور تأثير متسلسل.
وتشير الإحصائيات التي تم جمعها خلال الحادثة إلى أن معظم الصعوبات التي واجهها المستخدمون، حوالي 46%، كانت مرتبطة بالاتصال المباشر بالخادم. وشكلت المشاكل في نظام أسماء النطاقات (DNS) 29% من الحالات، في حين شكلت حالات الفشل في واجهة برمجة التطبيقات (API) 18%. توضح هذه الأرقام أن الفشل أثر على ركائز متعددة لتشغيل الشبكة، مما يعرض كلاً من دقة العنوان والتسليم الفعال للبيانات للخطر.
على الرغم من أن البنية التحتية لـ Cloudflare مصممة للتكرار العالي، إلا أن تزامن الأخطاء عبر ناقلات الخدمة المختلفة جعل من الصعب إعادة توجيه حركة المرور تلقائيًا. ارتفع زمن الاستجابة، أو وقت الاستجابة بين طلب المستخدم واستجابة الخادم، إلى مستويات جعلت اتصال البيانات في الوقت الفعلي أمرًا مستحيلًا، وهو أمر ضروري للألعاب عبر الإنترنت والمعاملات الرقمية في متجر المنصة.
الاختلاف في حالات النظام
خلال فترة عدم الاستقرار، كان هناك تناقض ملحوظ بين تصورات اللاعب وتقارير الحالة الرسمية من Steam. بينما لم يتمكن الملايين من المستخدمين من تسجيل الدخول أو شراء الألعاب، أشارت لوحات معلومات المراقبة الخاصة بشركة Valve إلى أن Steam Store والمجتمع وWeb API يعملون بشكل طبيعي. يحدث هذا الموقف لأن الأنظمة الداخلية للمنصة قد تكون عاملة، ولكن “الطريق” الذي يأخذ المستخدم إليها – شبكة توصيل المحتوى – كان مسدودًا.
ومع ذلك، لم تظهر جميع الأنظمة الفرعية سالمة. شهدت مخزونات لاعبي لعبة Counter-Strike تأخيرات كبيرة، مما منع عرض العناصر الافتراضية وإدارتها. يؤثر هذا النوع من الفشل بشكل مباشر على اقتصاد اللعبة وتجربة المستخدم، مما يؤدي إلى حظر المعاملات ومنع استخدام المظاهر والمعدات أثناء المباريات، مما أدى إلى ظهور شكاوى محددة داخل مجتمع مطلق النار التكتيكي.
مديرو الاتصال (CMs)، المسؤولون عن توجيه اللاعبين إلى الخوادم المناسبة، لديهم معدل توفر يبلغ 93.7%. وعلى الرغم من أنه يبدو رقمًا مرتفعًا، على مقياس ملايين المستخدمين المتزامنين، إلا أن نسبة 6.3% المتبقية تمثل فشلًا قادرًا على قطع الاتصال بمئات الآلاف من الأشخاص. أدى الحمل الزائد على هذه العقد المتبقية، إلى جانب عدم القدرة على التوجيه عبر Cloudflare، إلى إنشاء سيناريو “التعتيم” الذي يعاني منه المستهلكون.
Leia Também

اختبار البطارية الجديد يضع هاتف Galaxy S26 Ultra في المقدمة على iPhone 17 Pro Max في التصنيف العالمي

تكشف الأبحاث أن الآباء لا يدركون كيفية استخدام أطفالهم للذكاء الاصطناعي

خصم كبير على هاتف Galaxy S25 Plus يخفض قيمته إلى أقل من 4500 ريال في المتجر الإلكتروني
مراقبة الوضع الدولي
كشف التوزيع الجغرافي للأخطاء عن سيناريو غير متجانس. في أوروبا، تمكنت مدن مثل أمستردام ولندن من الحفاظ على مديري الاتصال في حالة مستقرة، بينما أبلغت فرانكفورت وستوكهولم وفيينا عن “حمل مرتفع”، مما يشير إلى أن خوادمها كانت تعمل بكامل طاقتها لمحاولة التعويض عن فشل الشبكة. قدمت هلسنكي صورة مختلطة، مع عدم توفر البيانات للاتصال العام، ولكن الاستقرار في خدمات محددة من Counter-Strike.
وفي القارة الأمريكية، أظهرت البنية التحتية مرونة نسبية أكبر. حافظت مراكز البيانات الكبيرة في الولايات المتحدة، بما في ذلك أتلانتا وشيكاغو ودالاس ولوس أنجلوس وسياتل، على عملياتها عند حمل منخفض أو عادي. في أمريكا الجنوبية، سجلت نقاط الاتصال في ساو باولو وبوينس آيرس وليما وسانتياغو أيضًا حالة تشغيلية، مما يشير إلى أن حركة المرور في هذه المناطق ربما تم توجيهها عبر مسارات بديلة أو أن فشل Cloudflare كان له معدل حدوث أقل على العقد المحلية في ذلك الوقت المحدد.
ومن ناحية أخرى، واجهت آسيا صعوبات كبيرة. وتم تصنيف هونغ كونغ على أنها “مثقلة بالأعباء”، مما يشير إلى أن الطلب تجاوز قدرة المعالجة المتاحة خلال الأزمة. كما أبلغت دبي وسنغافورة عن أحمال عالية. وفي الصين، أظهرت مراكز مهمة مثل بكين وغوانغدونغ عدم توفر البيانات لمديري الاتصال، مما يشير إلى انقطاع شديد في الوصول إلى واحدة من أكبر قواعد اللاعبين في العالم.
الضعف في شبكات التوزيع
وتزامن حادث 20 فبراير أيضًا مع تقارير عن عدم الاستقرار في أكاماي، وهو عملاق آخر للبنية التحتية للإنترنت. أبلغت الشركة عن حالات فشل متكررة في نظام توفير الشهادات الخاص بها، على الرغم من عدم وجود رابط مباشر مؤكد لانقطاع Cloudflare. إن حدوث مشكلات متزامنة في اثنين من أكبر مزودي خدمات CDN في العالم يثير تنبيهًا بشأن الهشاشة النظامية لشبكة الكمبيوتر العالمية.
بالنسبة للمستهلك النهائي، فإن التمييز بين مقدم الخدمة الفاشل ليس له أهمية نظرا لاستحالة استخدام الخدمة المتعاقد عليها. وسيطر الإحباط على المنتديات ووسائل التواصل الاجتماعي، حيث أبلغ اللاعبون عن التوقف المفاجئ للمباريات التنافسية وفقدان التقدم في المباريات. إن طبيعة الألعاب الحديثة “المتصلة بالإنترنت دائمًا” تجعل انقطاعات الخدمة هذه ضارة بشكل خاص بسمعة المنصات.
تواصل فرق هندسة الشبكات مراقبة استقرار الأنظمة لمنع تكرار الحادث. سيكون تحليل ما بعد الفشل حاسمًا لفهم كيفية فشل التكرار في التخفيف من التأثير الأولي وما هي التدابير التي يمكن تنفيذها لضمان أن الفشل في خدمة DNS أو CDN لا يؤدي إلى شل الوصول إلى منصات الترفيه العالمية في المستقبل تمامًا.