Global failure at Cloudflare interrupts Steam services and frustrates players in several countries

A severe outage in content distribution systems hit internet infrastructure on the afternoon of February 20, blocking access to the Steam platform on a global scale. The incident began at around 1:38 pm, Austin time, and resulted in a massive volume of complaints from users who were unable to access their game libraries and online services. The problem was traced to failures in the Cloudflare servers, a network essential for the operation and security of large portals, triggering a chain reaction that affected the connectivity of millions of people.
Real-time monitoring data highlighted the magnitude of the event, recording a peak of 431,000 page views on a website specialized in tracking service outages, all in the space of just one hour. The failure was not restricted to a specific region, quickly spreading across several continents and exposing the critical dependence that digital entertainment services have on content delivery networks (CDNs) and distributed DNS systems.
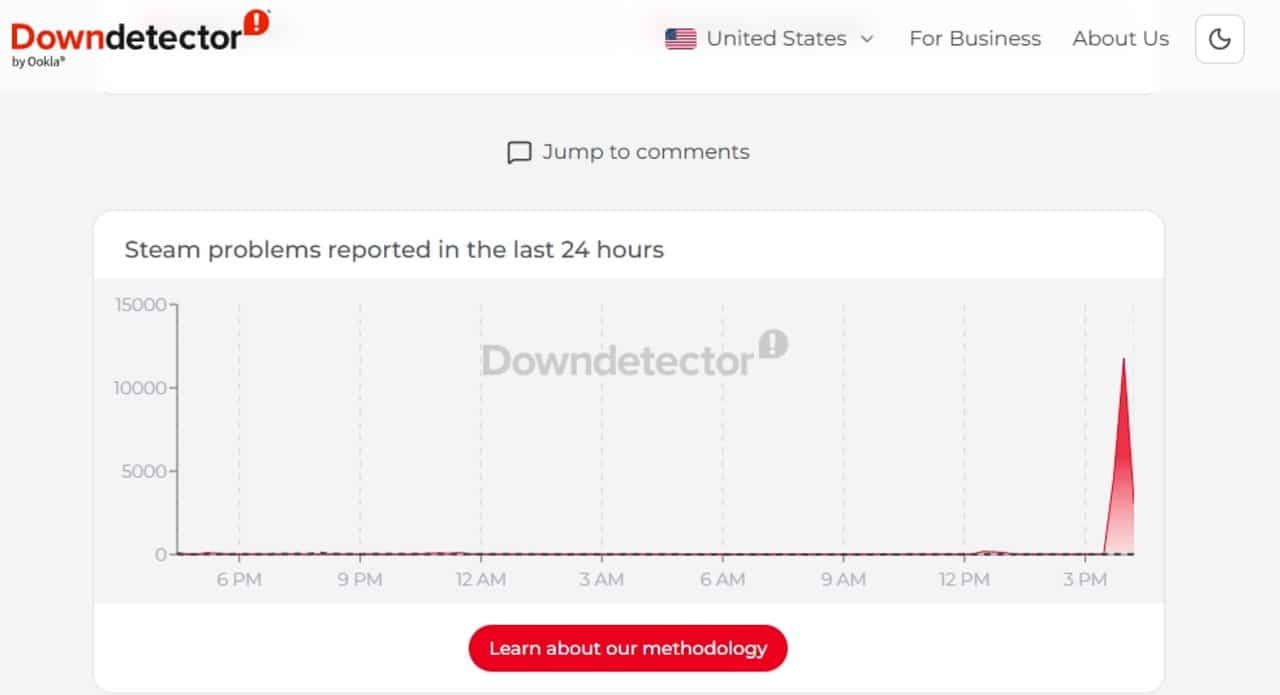
Cloudflare acted to identify the source of the instability, publicly acknowledging the existence of connectivity errors in its infrastructure. Technicians observed a significant increase in error rates on the 1.1.1.1 service home page, as well as complications in bot management and the Workers AI service. Outro critical point identified was the high latency in HTTP requests processed by the Newark data center (EWR), which contributed decisively to the slowness and inaccessibility perceived by end users.
Technical interruption diagnosis
The architecture of the modern internet depends on services like Cloudflare, which act as vital intermediaries between origin servers and users, offering protection against DDoS attacks and traffic optimization. Quando this intermediate layer fails, access to the final service is cut off, even if the gaming company’s servers are operating normally. The complexity of this interdependence became clear when problems located in specific nodes of the network generated a cascade effect.
Statistics collected during the incident indicate that most of the difficulties faced by users, around 46%, were related to the direct connection to the server. Problemas in the domain name system (DNS) accounted for 29% of occurrences, while failures in the application programming interface (API) accounted for 18%. Esses numbers demonstrate that the failure affected multiple pillars of network operation, compromising both address resolution and effective data delivery.
Even though the Cloudflare infrastructure is designed for high redundancy, the simultaneity of errors in different service vectors made it difficult to automatically redirect traffic. Latency, or the response time between the user’s request and the server’s response, rose to levels that made real-time data communication impossible, something essential for online games and digital transactions in the platform’s store.
Divergence in system statuses
During the period of instability, there was a notable discrepancy between player perceptions and Steam’s official status reports. Enquanto million users were unable to log in or purchase games, Valve monitoring panels indicated that Loja Steam, Comunidade and the Web API were operating within normal limits. Essa situation occurs because the platform’s internal systems may be functional, but the “road” that takes the user to them — the content delivery network — was blocked.
However, not all subsystems emerged unscathed. Counter-Strike player inventories have experienced significant delays, preventing the viewing and management of virtual items. Esse type of failure directly affects the game economy and user experience, blocking transactions and preventing the use of skins and equipment during matches, which generated specific complaints within the tactical shooter community.
The Gerenciadores of Conexão (CMs), responsible for directing players to the appropriate servers, had an availability rate of 93.7%. Embora may seem like a high number, on the scale of millions of simultaneous users, the remaining 6.3% represents a failure capable of disconnecting hundreds of thousands of people. The overload on these remaining nodes, coupled with the inability to route via Cloudflare, created the “blackout” scenario experienced by consumers.



Monitoring the international situation
The geographic distribution of faults revealed a heterogeneous scenario. Na Europa, cities like Amsterdã and Londres managed to keep their connection managers in stable status, while Frankfurt, Estocolmo and Helsinque presented a mixed picture, with data unavailable for general connection, but stability in specific Counter-Strike services.
On the American continent, infrastructure demonstrated greater relative resilience. Grandes data centers in Estados Unidos, including Atlanta, Chicago, Dallas, Los Angeles, and Seattle, maintained low or normal load operations. Na América of Sul, the connection points in São Paulo, Buenos Aires, Lima and
Ásia, on the other hand, faced considerable difficulties. Hong Kong was classified as “Overloaded”, indicating that demand exceeded available processing capacity during the crisis. Dubai and Singapura also reported high loads. Na China, important centers such as Pequim and Guangdong showed data unavailability for connection managers, pointing to a severe interruption in access to one of the largest player bases in the world.
Vulnerability in distribution networks
The February 20 incident also coincided with reports of instability at Akamai, another giant in the internet infrastructure sector. The company reported recurring failures on its Sistema of Provisionamento of Certificados, although there was no confirmed direct link to the Cloudflare outage. The simultaneous occurrence of problems in two of the largest CDN providers in the world raises an alert about the systemic fragility of the global computer network.
For the end consumer, the distinction between which provider is failing is irrelevant given the impossibility of using the contracted service. Frustration took over forums and social media, where players reported the abrupt interruption of competitive matches and the loss of progress in games. The “always online” nature of modern gaming makes these outages particularly damaging to the platforms’ reputations.
Network engineering teams continue to monitor systems stability to prevent replicas of the incident. Post-failure analysis will be crucial to understanding how redundancy failed to mitigate the initial impact and what measures can be implemented to ensure that a failure in a DNS or CDN service does not completely paralyze access to global entertainment platforms in the future.
Veja Tambem em News (EN)

Research reveals that parents are unaware of how their children use artificial intelligence

Samsung releases new system update with new features for Galaxy Watch 4 users

Digital retail reduces the value of the Galaxy S25 5G smartphone with bank bonuses and device exchange

Amazon’s wireless CarPlay adapter has a 50% discount and high approval ratings from drivers

Zach Cregger’s new Resident Evil ignores games and focuses on an unprecedented story with new characters

Rumor suggests that Nintendo is preparing a special edition of the Switch 2 with a remake of Ocarina of Time

Apple accelerates production of the iPhone 17e and develops new Air model with dual camera system

Epic Games platform releases twelve high-budget games at no permanent cost for PC users

PlayStation 5 Pro price drop accelerates digital retail sales and eliminates global stocks

New Galaxy Watch 9 firmware appears on server and confirms progress in software development

Apple’s commemorative project tests cell phone with 1.1 millimeter edge and curved screen for 2027
