Global blackout in Cloudflare infrastructure takes down thousands of websites and affects DNS routes

Responsible for managing the traffic of approximately twenty percent of the entire internet, Cloudflare has recently recorded serious fluctuations in its content distribution network. This technology giant acts as a vital security and performance intermediary between hosting servers and end-user devices. When a failure occurs in this gigantic protection and routing mesh, the domino effect reaches global proportions in a matter of minutes. Consequently, thousands of web pages are down, displaying loading failure messages to people trying to access entertainment, work or e-commerce platforms.
Tracking instabilities and complaints registered by the digital community
As soon as the first signs of a drop appeared, technology professionals and ordinary users began to document access difficulties on forums and websites specializing in service monitoring. These collaborative diagnostic portals made it possible to precisely identify the exact points of rupture in the digital architecture. The most frequent complaints pointed to severe crashes in website administration panels, inaccessibility in databases, failures in virtual machines and extreme slowness in remote storage and user authentication services.
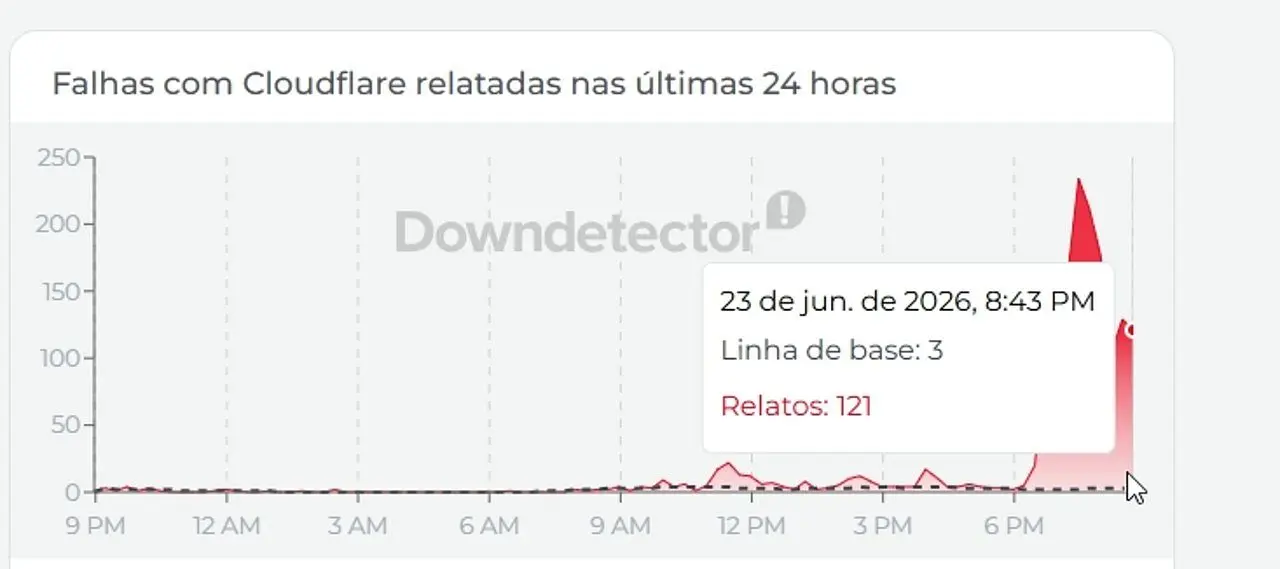
Analysis of the performance graphs throughout the day showed that the problem was not limited to a quick drop, but to a cycle of instabilities that lasted for more than twenty-four hours. This up and down on control panels showed that the company’s technicians fought a complex battle to normalize the flow of information. Independent status checking tools were crucial in separating local problems from general failure, revealing that brief moments of return to normality were quickly followed by new blackouts, creating headaches for support teams in several countries.
Technical diagnosis points out the sectors most affected by the connection drop
In order to measure the structural damage, network analysts compiled the volume of error calls to map which internet gears stopped turning. Cross-referencing this statistical information indicated that the core of the collapse occurred in the primary communication layer. This interruption temporarily paralyzed sales in virtual stores, blocked the updating of major press vehicles and prevented the exchange of messages in corporate applications, dividing it into three main failure fronts.
- Impossibility of establishing a direct connection with the origin servers, a scenario that dominated the statistics with fifty-six percent of reports.
- Collapse in domain name resolution, the famous system that translates web addresses, responsible for twenty-six percent of notifications.
- Breaks in communication with application programming interfaces, representing eleven percent of the total complaints tallied.
The significant number of failures in domain resolution justifies why white screens with error codes 502 or 522 dominated browsers during the incident. Without the ability to convert a user’s typed website name into a numeric IP address that computers understand, browsing becomes completely blind and aimless. This episode sheds light on an old debate in the technology community: the extreme vulnerability and dependence of the global market on a very small number of network infrastructure providers.
Leia Também

Messi reaches 19 goals in FIFA World Cups with great free kick for Argentina in clash with Jordan

Cristiano Ronaldo shines beyond the pitch at the 2026 World Cup with business empire and family luxury

At 41, Cristiano Ronaldo reaffirms his historic legacy and prepares to shine in the 2026 World Cup
Global extent of the problem and mitigation strategies for companies
The true scale of the blackout was evident when looking at heat maps generated by fault detection platforms, which illustrated the origin of each error warning triggered. Geolocation graphics confirmed that the crisis did not spare any continent, triggering simultaneous red alerts in several global metropolises. This occurred mainly in regions where the provider’s data processing centers faced the biggest bottlenecks in dispatching the information packages requested by internet users.
For large corporations, where seconds of downtime translate into millions of dollars lost and irreparable damage to reputation, the adoption of contingency plans was immediate. Information technology departments used high-level monitoring software to quickly isolate the fault. Based on this agile diagnosis, the experts were able to redirect their customers’ traffic to secondary routes and backup servers, minimizing the impact on end-to-end operations while the main supplier worked on definitively correcting the system.
Reliability metrics and the mobilization of web developers
Aiming to maintain the trust of the corporate market, the digital security giant provides public panels where it is possible to audit the stability of its services over a full quarter. This operational availability record is open for consultation at any time, serving as an essential transparency tool. Infrastructure professionals use this historical data to assess risks before migrating large projects to the cloud or employing advanced protections against massive malicious traffic attacks.
In parallel with corporate communications, online communities of programmers have become true crisis committees for sharing alternative routes and temporary code adjustments. To ensure these forums didn’t devolve into a chaos of empty complaints, moderators enforced strict coexistence guidelines during the peak of the problem. The requirement for detailed technical reports and the fight against out-of-context messages ensured that the collective effort resulted in practical solutions to keep sites running until full network stability was declared.













