La panne mondiale de l’infrastructure Cloudflare supprime des milliers de sites Web et affecte les routes DNS.

Responsable de la gestion du trafic d’environ vingt pour cent de l’ensemble de l’Internet, Cloudflare a récemment enregistré de graves fluctuations dans son réseau de distribution de contenu. Ce géant de la technologie agit comme un intermédiaire vital en matière de sécurité et de performances entre les serveurs d’hébergement et les appareils des utilisateurs finaux. Lorsqu’une panne survient dans ce gigantesque maillage de protection et de routage, l’effet domino atteint des proportions mondiales en quelques minutes. Par conséquent, des milliers de pages Web sont en panne, affichant des messages d’échec de chargement aux personnes essayant d’accéder aux plateformes de divertissement, de travail ou de commerce électronique.
Suivi des instabilités et des plaintes enregistrées par la communauté numérique
Dès les premiers signes de baisse, les professionnels de la technologie et les utilisateurs ordinaires ont commencé à documenter les difficultés d’accès sur les forums et sites spécialisés dans la surveillance des services. Ces portails de diagnostic collaboratifs ont permis d’identifier précisément les points exacts de rupture de l’architecture numérique. Les plaintes les plus fréquentes concernaient de graves pannes dans les panneaux d’administration des sites Web, l’inaccessibilité des bases de données, des pannes de machines virtuelles et une extrême lenteur des services de stockage à distance et d’authentification des utilisateurs.
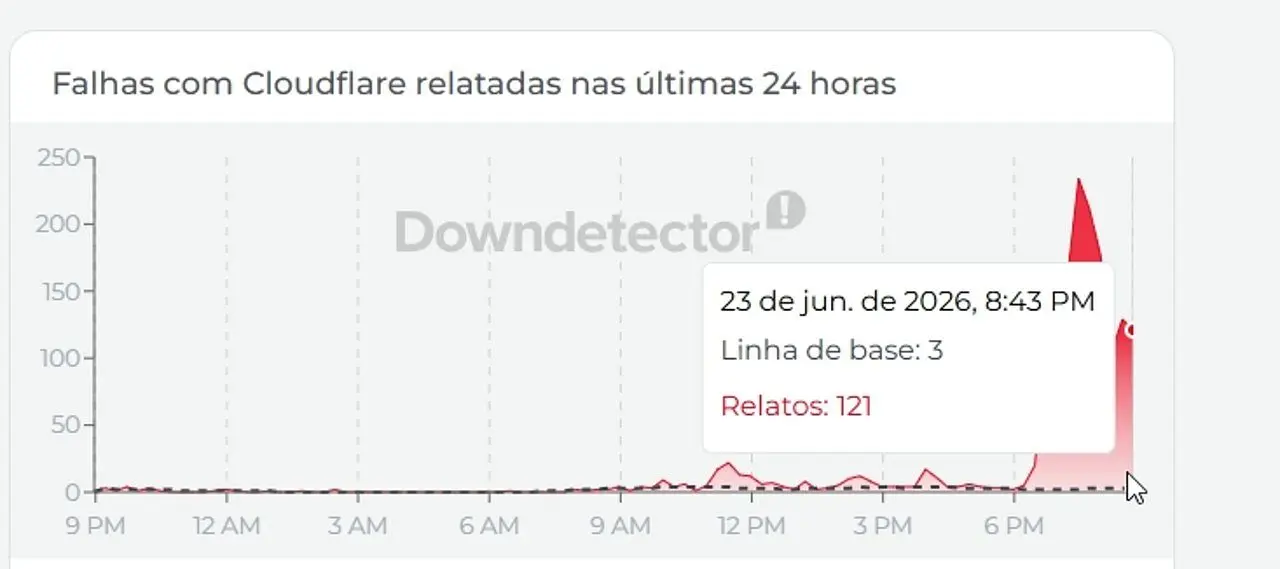
L’analyse des graphiques de performances tout au long de la journée a montré que le problème ne se limitait pas à une baisse rapide, mais à un cycle d’instabilités qui durait plus de vingt-quatre heures. Ces mouvements de haut en bas sur les panneaux de contrôle ont montré que les techniciens de l’entreprise ont mené une bataille complexe pour normaliser le flux d’informations. Les outils indépendants de vérification de l’état ont joué un rôle crucial pour séparer les problèmes locaux des échecs généraux, révélant que de brefs instants de retour à la normale étaient rapidement suivis de nouvelles pannes, créant des maux de tête pour les équipes d’assistance dans plusieurs pays.
Le diagnostic technique pointe les secteurs les plus touchés par la baisse de connexion
Afin de mesurer les dommages structurels, les analystes du réseau ont compilé le volume d’appels d’erreur pour cartographier les engrenages Internet qui ont cessé de tourner. Le croisement de ces informations statistiques a indiqué que le cœur de l’effondrement s’est produit dans la couche de communication principale. Cette interruption a temporairement paralysé les ventes dans les magasins virtuels, bloqué la mise à jour des principaux véhicules de presse et empêché l’échange de messages dans les applications d’entreprise, le divisant en trois fronts principaux de défaillance.
- Impossibilité d’établir une connexion directe avec les serveurs d’origine, un scénario qui dominait les statistiques avec cinquante-six pour cent des signalements.
- Effondrement de la résolution des noms de domaine, le fameux système de traduction des adresses Web, responsable de vingt-six pour cent des notifications.
- Les ruptures de communication avec les interfaces de programmation d’applications représentent onze pour cent du total des plaintes recensées.
Le nombre important d’échecs dans la résolution de domaine explique pourquoi les écrans blancs avec les codes d’erreur 502 ou 522 ont dominé les navigateurs lors de l’incident. Sans la possibilité de convertir le nom de site Web saisi par un utilisateur en une adresse IP numérique compréhensible par les ordinateurs, la navigation devient complètement aveugle et sans but. Cet épisode met en lumière un vieux débat au sein de la communauté technologique : l’extrême vulnérabilité et la dépendance du marché mondial à l’égard d’un très petit nombre de fournisseurs d’infrastructures de réseaux.
Leia Também

Messi atteint 19 buts en Coupe du Monde de la FIFA avec un superbe coup franc pour l’Argentine lors du choc contre la Jordanie

Cristiano Ronaldo brille au-delà du terrain lors de la Coupe du monde 2026 avec son empire commercial et son luxe familial

A 41 ans, Cristiano Ronaldo réaffirme son héritage historique et se prépare à briller lors de la Coupe du Monde 2026
Étendue mondiale du problème et stratégies d’atténuation pour les entreprises
La véritable ampleur de la panne était évidente en regardant les cartes thermiques générées par les plateformes de détection de pannes, qui illustraient l’origine de chaque avertissement d’erreur déclenché. Les graphiques de géolocalisation ont confirmé que la crise n’a épargné aucun continent, déclenchant des alertes rouges simultanées dans plusieurs métropoles mondiales. Cela s’est produit principalement dans les régions où les centres de traitement des données du fournisseur ont été confrontés aux plus grands goulots d’étranglement dans l’acheminement des paquets d’informations demandés par les internautes.
Pour les grandes entreprises, où quelques secondes d’arrêt se traduisent par des millions de dollars perdus et des dommages irréparables à leur réputation, l’adoption de plans d’urgence a été immédiate. Les services informatiques ont utilisé un logiciel de surveillance de haut niveau pour isoler rapidement le défaut. Sur la base de ce diagnostic agile, les experts ont pu rediriger le trafic de leurs clients vers des routes secondaires et des serveurs de secours, minimisant ainsi l’impact sur les opérations de bout en bout pendant que le fournisseur principal travaillait à corriger définitivement le système.
Métriques de fiabilité et mobilisation des développeurs web
Dans le but de maintenir la confiance du marché des entreprises, le géant de la sécurité numérique propose des panels publics où il est possible d’auditer la stabilité de ses services sur un trimestre complet. Ce registre de disponibilité opérationnelle est consultable à tout moment et constitue un outil de transparence indispensable. Les professionnels de l’infrastructure utilisent ces données historiques pour évaluer les risques avant de migrer de grands projets vers le cloud ou d’utiliser des protections avancées contre les attaques massives de trafic malveillant.
Parallèlement aux communications d’entreprise, les communautés en ligne de programmeurs se sont transformées en véritables comités de crise pour partager des itinéraires alternatifs et des ajustements temporaires de code. Pour garantir que ces forums ne se transforment pas en un chaos de plaintes vides de sens, les modérateurs ont appliqué des directives strictes de coexistence au plus fort du problème. L’exigence de rapports techniques détaillés et la lutte contre les messages hors contexte ont permis de garantir que l’effort collectif aboutisse à des solutions pratiques pour maintenir les sites en fonctionnement jusqu’à ce que la stabilité totale du réseau soit déclarée.













